
O conceito de “variáveis locais”, como estamos habituados em linguagens de programação de mais alto nível, não tem equivalência direta em assembly.
IMPORTANTE: Todos os códigos em assembly compartilhados nessa série omitem verificações e, para fins de simplicidade, não estão otimizados.
Na prática, o desafio é determinar, dentre as alternativas disponíveis, a forma mais eficiente para armazenar e recuperar, de alguma forma, dados na memória tornando-os acessíveis para processamento pelo código. Escolhas infelizes geralmente implicam em performance mais pobre.
#include <iostream>
int summarize(const int value)
{
auto result = 0;
for (auto i = 1; i <= value; i++)
{
result += i;
}
return result;
}
int main() {
std::cout << "summarize(10) = " << summarize(10) << std::endl;
}
O mais eficiente costuma ser utilizar os registradores do processador. Embora eles tenham pouca capacidade, estão montados fisicamente junto ao processador o que torna sua velocidade de acesso imbatível.
Os compiladores geralmente utilizam os registradores para, por exemplo, armazenar valores de contadores e acumuladores em loops.
.model flat,c
.code
summarize_ proc
push ebp
mov ebp, esp
push ebx
xor eax, eax ; result = 0;
mov ebx, 1
mov ecx,[ebp+8] ; ecx = value
jmp check_for_is_complete
for_body:
add eax, ebx
inc ebx
check_for_is_complete:
cmp ebx, ecx
jg finish
jmp for_body
finish:
pop ebx
pop ebp
ret
summarize_ endp
end
Importante que lembremos que os registradores que utilizamos em nossas funções são os mesmos disponíveis para todo o código. Dependendo da convenção adotada, alguns registradores podem ser voláteis ou não-voláteis. Registradores não-voláteis devem ter seu valor restaurado sempre antes da função retornar (como ebx e ebp no exemplo). Registradores voláteis podem ter seus valores modificados livremente.
Outra alternativa comum é alocar espaço na stack para acomodar o valor das variáveis.
#include <iostream>
int summarize(const int a, const int b)
{
const auto max = (a > b) ? a : b;
const auto min = (a < b) ? a : b;
return (max * (max + 1) - (min - 1) * min) / 2;
}
int main() {
std::cout << "summarize(10) = " << summarize(100, 1) << std::endl;
}
Quando utilizamos a stack para armazenar os valores de variáveis locais, é comum “reservar” espaço logo no início da função (trecho de código conhecido como prólogo) e garantir que o espaço alocado seja liberado no final da função (trecho de código conhecido como epílogo).
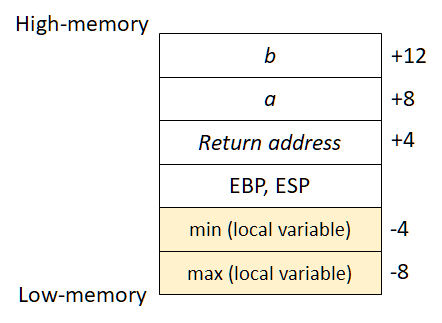
A prática comum é colocar os valores das variáveis locais logo após o registrador ebp. Dessa forma, parâmetros para as funções são acessados com deslocamentos positivos e variáveis são acessadas com deslocamentos negativos.
.model flat,c
.code
summarize_ proc
push ebp
mov ebp, esp
sub esp, 8 ; allocating space on the stack for two integers
mov eax,[ebp+8] ; eax = 'a'
mov ecx,[ebp+12] ; ecx = 'b'
cmp eax, ecx
jle aIsMax
mov [ebp - 8], eax ; max = a
jmp resume_1
aIsMax:
mov [ebp - 8], ecx ; max = b
resume_1:
cmp eax, ecx
jge aIsMin
mov [ebp - 4], eax ; min = a
jmp resume_2
aIsMin:
mov [ebp - 4], ecx ; min = b
resume_2:
mov eax, [ebp - 8] ; eax = max
add eax, 1
imul eax, [ebp - 8]
mov ecx, [ebp - 4] ; ecx = min
sub ecx, 1
imul ecx, [ebp - 4]
sub eax, ecx
cdq
sar eax, 1
mov esp, ebp ; releasing local storage space
pop ebp
ret
summarize_ endp
end
Obviamente, nada disso é relevante quando estamos escrevendo código em Java, C++ ou C#. Por sorte, os compiladores fazem um ótimo trabalho escondendo esses “detalhes” do nosso dia a dia.
Objetos complexos, armazenados na heap, tem apenas seus endereço armazenado localmente (também em registradores ou na stack).